Waarom jouw AI agent doet wat je zegt, maar niet wat je bedoelt
Als oud-militair en inmiddels (10 jaar) software (QA) developer merk ik aan alle kanten hoe de ‘software-wereld’ momenteel kampt en worstelt met het vraagstuk hoe je werkelijk kunt versnellen en tevens effectief sturen in een omgeving (van AI Agents) die je niet volledig kunt controleren.
In de krijgsmacht denkt men daar al eeuwen over na. Een filosofie die exact hier over gaat is ‘mission command’. Een afgeleide van de Pruisische ‘auftragstaktik’, wat een gecentraliseerde intentie (de ‘waarom’ en ‘wat’) combineert met een gedecentraliseerde uitvoering (de ‘hoe’).
Toen ik (compleet) overging naar het bouwen van software met de hulp van AI agents, merkte ik meteen dat dezelfde vragen opduiken: ‘Hoeveel autonomie geef je/wil je geven?’, ‘Hoe bouw je vertrouwen op in iets wat je niet kunt overzien?’, ‘Ga ik alle (supersnel) gerealiseerde output alsnog zelf volledig doorspitten en controleren?’ Nee! Dan ben ik mijn voordeel kwijt en kan ik (alsnog) niet versnellen.
De militaire mission command doctrine heeft antwoorden die verrassend goed vertalen naar het effectief aansturen van autonome AI-systemen: ‘Agents’.
Het probleem dat niemand hardop benoemt
Je werkt met een AI agent: een autonoom systeem dat zelfstandig redeneert, beslissingen neemt, tools aanroept en subtaken uitvoert, soms in samenwerking met andere agents. Je geeft een agent gedetailleerde instructies. Hij voert ze uit. En toch klopt het resultaat niet. Niet omdat de agent het verkeerd deed, maar omdat hij juist precies deed wat jij zei, terwijl jij iets anders bedoelde. Dit is het centrale probleem bij het aansturen van AI agents. Niet technisch falen, maar een fundamenteel misverstand of onwetendheid over hoe autonome systemen effectief worden aangestuurd.
De meeste oplossingen die je tegenkomt gaan in dezelfde richting: meer detail, meer stappen, meer controle. Uitputtender instrueren. En hoewel dit wellicht het gevoel van controle lijkt te bevorderen, wordt het resultaat er vaak niet beter op.
De krijgsmacht heeft dit probleem al eeuwen geleden (h)erkend. En opgelost. Een goede generaal zal nooit tegen zijn (onder-)commandanten zeggen: “Win de oorlog en doe dit zonder verliezen te leiden”. En daarom zeg ik ook niet (meer) tegen mijn agent: “Bouw dit systeem, maak het fantastisch en (oja:) maak geen fouten.”
Helmuth von Moltke en het probleem van gedelegeerde autonomie
Helmuth von Moltke (‘the Elder’) was chef-staf van het Pruisische leger in de tweede helft van de negentiende eeuw. Hij leidde zijn troepen door drie oorlogen en won ze alle drie. Niet door zijn mensen strakker te controleren, maar door beter te begrijpen hoe autonomie werkt. Zijn inzicht was scherp en tegendraads: een gedetailleerd bevel is een illusie van controle. Zodra de situatie verandert (en op het slagveld verandert de situatie altijd) is het bevel al achterhaald. De uitvoerder die alleen zijn instructies kent, staat dan met lege handen. De uitvoerder die de intentie kent, kan doorgaan en handelen. Dit werd ‘Auftragstaktik’: taakgerichte tactiek. In moderne westerse krijgsmachten, waaronder de Nederlandse, kennen we het als ‘mission command’. De kern: stuur op intentie, niet op instructie. Geef mensen het wat en het waarom en laat het hoe over aan degene die het dichtst op de situatie zit.
Instructie én intentie: twee verschillende lagen
Wie met AI agents werkt, werkt onvermijdelijk met instructies. Dit is niet fout. Dit is zelfs goed. Instructies en specifieke vaardigheden (ook wel ‘skills’) zijn essentieel om te zorgen dat een agent effectief kan werken en niet telkens ‘het wiel’ hoeft uit te vinden. De skills zijn de aangeleerde vaardigheden: een bestand lezen, een API aanroepen, een testrapport genereren. De agent voert ze deterministisch uit zodra hij ze aanroept. Maar de beslissing welke skill wanneer nodig is, welke volgorde logisch is, en wanneer geen enkele skill past en hij moet stoppen en vragen — dat is autonomie. En autonomie heeft intentie nodig, geen instructie.
Vergelijk het met een soldaat die weet hoe hij een goede vuurpositie bouwt, camouflagetechnieken toepast, zijn wapensysteem(en) goed onderhoudt en weet te bedienen wanneer het moet. Dit hoeft niet expliciet verteld te worden tijdens een bevelsuitgifte. Echter moet de soldaat dus wel (ergens) de instructie hebben gehad en de vaardigheid hebben verworven om het nu goed te kunnen toepassen. De commandant moet op zijn beurt dus op de hoogte zijn van de aanwezige skills. Pas dan zal zijn intentie, “het effectief kunnen afslaan van een verwachte aanval op locatie X vanuit richting X”, resulteren in goed opgebouwde vuurposities van waaruit succesvol de inkomende aanval werd afgeslagen.
Het is dus belangrijk ‘instructie’ en ‘intentie’ niet tegen elkaar uit te willen spelen, maar wel het verschil kunnen herkennen. De twee zijn complementair aan elkaar. Je kunt het beter zien als twee ‘lagen’.

De onderste laag bestaat uit skills (vaardigheden): herhaalbare, gestructureerde stappenplannen voor een agent. Een skill beschrijft exact wat de agent moet doen in een bekende situatie. Dat is automatisering. En automatisering is waardevol. Als je weet wat er moet gebeuren en hoe, is een skill de juiste keuze: deterministisch, voorspelbaar, beheersbaar.
Maar automatisering is niet hetzelfde als autonomie. Autonomie is de laag daarboven.
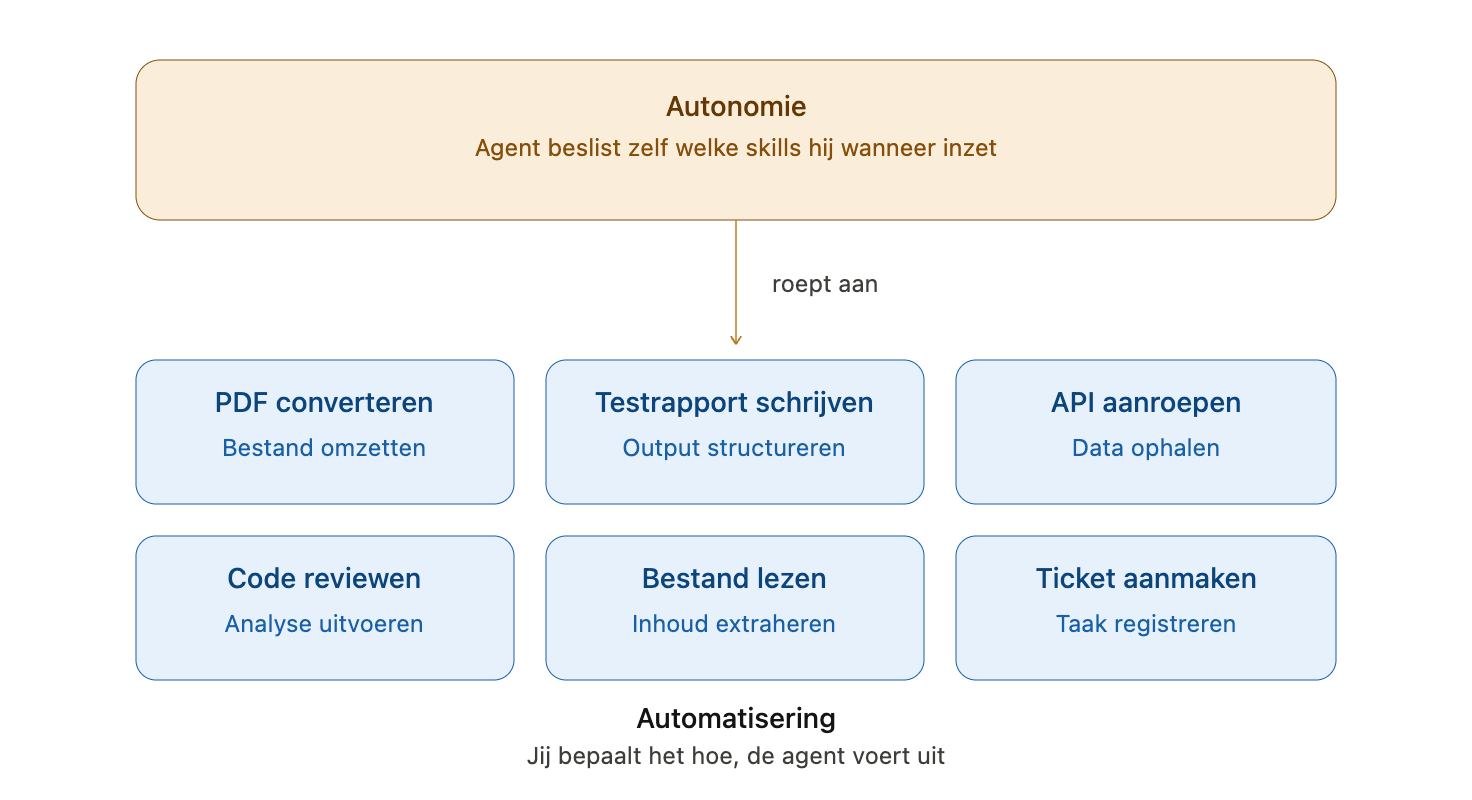
Mission command gaat over die bovenste laag. Niet over hoe je skills schrijft, maar over hoe je intentie overdraagt aan iets wat zelfstandig moet kunnen beslissen. Beide lagen hebben hun plaats. De fout die mensen maken is het toepassen van de onderste laag op situaties die de bovenste vereisen.
Waarom ‘mission command’ van toepassing is op AI agents
Een AI agent is een autonoom systeem dat zelfstandig redeneert, beslissingen neemt, tools aanroept en subtaken uitvoert, soms in samenwerking met andere agents. Je stelt het systeem in, geeft het een doel, en laat het los. Het geheel opereert grotendeels buiten jouw directe zicht. Dat is exact de situatie waarvoor mission command is ontwikkeld. En de vraag die Von Moltke zichzelf stelde — hoe geef ik richting aan autonomie die ik niet volledig kan controleren — is de vraag die elke engineer, architect en tech lead zich zou moeten stellen bij het bouwen van agent-systemen.
De zeven principes van mission command vertalen verrassend goed naar een aansturingsstrategie voor AI agents. Al kent die vertaling haar grenzen, zoals we aan het einde zullen zien.
De zeven principes als aansturingsstrategie
01 — Competence: bouw bekwaamheid voordat je autonomie geeft
Militair — Tactisch en technisch bekwame commandanten, ondergeschikten en teams vormen de basis van effectief mission command. Autonomie zonder bekwaamheid is roekeloos. Een soldaat die zijn vak niet beheerst, kan de intentie van zijn commandant niet waarmaken, hoeveel vrijheid hij ook krijgt.
Agent — Een agent is zo goed als zijn training, tools en context. Garbage in, garbage out. Voordat je een agent autonoom laat opereren, moet je weten waartoe hij in staat is en waartoe niet. Competence bij agents bouw je op door de juiste tools te geven, de juiste context mee te geven, en de grenzen van zijn kunnen te kennen voordat je hem loslaat.
Scenario — Claude Code — Je wilt een complexe architectuurbeslissing uitwerken: je applicatie groeit en je twijfelt welke aanpak het beste past bij je schaalbaarheids- en beveiligingseisen. Je gooit de vraag naar het eerste het beste model, lekker snel en goedkoop. Het antwoord klinkt plausibel. Het is ook oppervlakkig. Competence-first betekent hier: kies het juiste model voor de zwaarte van de taak. Een snelle codeer-taak (een hulpfunctie schrijven, een test genereren) past bij een snel en licht model zoals Haiku. Maar een architectuurvraag met langetermijngevolgen verdient Opus: meer redeneerdiepte, meer vermogen om tegenstrijdige overwegingen echt tegen elkaar af te wegen. Het equivalent in de krijgsmacht: je stuurt geen antitankeenheid om een strategische verkenning uit te voeren. Andersom stuur je geen verkenningseenheid om een stel tanks uit te schakelen.
02 — Mutual trust: vertrouwen is verdiend, niet aangenomen
Militair — Een commandant die zijn mensen nooit heeft getest, weet niet wat hij loslaat. Vertrouwen in de krijgsmacht is opgebouwd door oefeningen, debriefings en gedeelde ervaring onder druk. Pas als dat bewijs er is, rechtvaardigt autonomie zichzelf. Vertrouwen werkt ook omgekeerd: de uitvoerder moet erop kunnen vertrouwen dat zijn commandant hem de ruimte geeft om te handelen. En een goede uitvoerder die twijfelt, vraagt. Dat is geen zwakte, dat is discipline.
Agent — Autonomie zonder evals is roekeloos, niet efficiënt. Evals zijn de oefeningen van het agent-systeem: gestructureerde tests die aantonen dat de agent binnen de intentie handelt als het erop aankomt. Vertrouwen bouw je op door te observeren, te testen en bij te sturen, niet door te hopen. Maar vertrouwen werkt ook de andere kant op: geef je agent expliciet de ruimte om bij twijfel te stoppen en de vraag terug te leggen. Een agent die onzeker is maar toch doorgaat, stapelt aannames op die je niet ziet. Een goede vraag is beter dan een plausibele gok.
Scenario — Claude Code — Je overweegt Claude Code volledig autonoom refactoring-taken te laten uitvoeren op een bestaande codebase zonder tussentijdse review. Dat is het equivalent van een kersverse militair, net uit zijn initiële opleiding, direct in een missiegebied dumpen bij een eenheid die hij nog niet kent. Misschien gaat het goed. Misschien niet. De vertrouwen-eerst aanpak: je begint met een afgebakende, lage-risico taak. Refactor één module, schrijf de tests, laat de CI draaien. Je reviewt het resultaat grondig. Dan een grotere taak. Dan nog een grotere. De autonomie groeit mee met het bewijs dat de agent binnen de intentie opereert. En je maakt expliciet dat stoppen en vragen altijd mag:
“Begin met de UserService module. Refactor naar de nieuwe structuur, zorg dat alle bestaande tests blijven slagen, en voeg tests toe voor elke edge case die je tegenkomt. Lever een samenvatting van je keuzes. Als je ergens twijfelt over de juiste aanpak, stop dan en stel de vraag. We beoordelen het resultaat voor we verdergaan.”
03 — Shared understanding: zorg dat iedereen hetzelfde plaatje heeft
Militair — Commandanten en ondergeschikten moeten een gedeeld begrip hebben van de missie, de situatie en elkaars rollen. Dat gedeelde begrip is niet hetzelfde als dezelfde informatie ontvangen. Het betekent dat iedereen de situatie op dezelfde manier interpreteert en weet hoe zijn eigen rol past in het grotere geheel.
Agent — In een multi-agent systeem is shared understanding het verschil tussen agents die samenwerken en agents die parallel langs elkaar heen werken. Elke agent moet niet alleen zijn eigen taak begrijpen, maar ook hoe zijn output aansluit op de input van de volgende agent en wat het systeem als geheel probeert te bereiken.
Scenario — Claude Code — Je laat Claude Code een nieuwe feature bouwen terwijl een collega tegelijkertijd werkt aan de database-laag. Claude bouwt de feature op aannames over de datastructuur die net zijn veranderd, maar niemand heeft hem dat verteld. Het resultaat integreert niet. Shared understanding ingebouwd:
“De database-laag is momenteel in ontwikkeling. De nieuwe schemawijzigingen staan gedocumenteerd in /docs/schema-v2.md. Gebruik die als uitgangspunt, niet de huidige code. Stem je interface-keuzes af op wat daar staat, niet op wat je in de bestaande code aantreft.”
04 — Commander’s intent: stuur op intentie, niet op instructie
Militair — De commandant formuleert helder wat bereikt moet worden en waarom, niet hoe. Een uitvoerder die alleen instructies kent, staat met lege handen zodra de situatie verandert. Een uitvoerder die de intentie kent, kan handelen, ook zonder dat zijn commandant erbij is.
Agent — Een agent die alleen instructies kent, loopt vast zodra de situatie afwijkt van het script. Een agent die de intentie kent, kan handelen. Het verschil zit niet in de lengte van je aansturing, maar in wat je daarin centraal stelt: het doel of de methode.
Scenario — Claude Code — Je vraagt Claude Code een authenticatiemodule te bouwen. De instructie-aanpak:
“Maak een bestand auth.ts. Voeg een functie toe genaamd validateToken. Gebruik JWT. Schrijf een unit test. Gebruik Jest.”
Claude voert het uit. Het werkt. Maar de tokens verlopen nooit, er is geen refresh-mechanisme, en de foutafhandeling is minimaal — want dat stond niet in de instructies. Je hebt gekregen wat je zei, niet wat je bedoelde. De intentie-aanpak:
“We bouwen een productie-waardige authenticatielaag voor een Next.js applicatie met meerdere tenants. Gebruikers moeten veilig kunnen inloggen en sessies moeten beheerbaar zijn. Kwaliteit en veiligheid gaan boven snelheid. Bepaal zelf de meest geschikte aanpak.”
05 — Mission orders: centraliseer de intentie, decentraliseer de uitvoering
Militair — Mission orders richten ondergeschikten op het overkoepelende doel, niet op de specifics van hoe ze hun taak moeten uitvoeren. Het wat ligt vast en komt van boven. Het hoe ligt zo laag mogelijk, bij degene die het dichtst op de situatie zit. Een commandant die elke tactische beslissing centraliseert, creëert een bottleneck en een organisatie die niet kan schalen onder druk.
Agent — Een agent die methodevrijheid heeft binnen een heldere uitkomstdefinitie, is veerkrachtiger en effectiever dan een agent die een vaste route volgt. Micromanagement van implementatiekeuzes is het meest tegendraadse principe voor engineers, en het meest de moeite waard om los te laten.
Scenario — Claude Code — Je wilt een caching-laag toevoegen aan je applicatie. De micromanagement-aanpak: je specificeert Redis, de exacte TTL-waarden, de sleutelstructuur en de invalidatiestrategie. Claude implementeert het precies zo, ook als hij gedurende de taak ontdekt dat jouw use case beter past bij een in-memory oplossing zonder de overhead van een externe service. De gedecentraliseerde aanpak:
“De applicatie heeft te veel databaseaanroepen bij veelgebruikte endpoints. Het doel is de responstijd onder de 200ms te krijgen zonder de databaselast te verhogen. Kies de meest passende aanpak voor onze stack en schaal, en licht je keuze toe.”
06 — Disciplined initiative: ontwerp voor verbreking, niet alleen voor het succesgeval
Militair — In mission command handelt een uitvoerder op basis van de intentie als communicatie wegvalt. Radioverbinding verbreekt, de commandant valt uit, het plan klopt niet meer met de werkelijkheid. De uitvoerder weet wat hij moet doen omdat hij de intentie kent, niet alleen het bevel. Dat oordeel — wanneer handelen, wanneer doorwerken ondanks obstakels — komt voort uit moreel besef, ervaring en gedeelde waarden. Het is niet aangeleerd via een instructie, het zit in de mens.
Agent — Bij agents is verbreking meer norm dan uitzondering. Tools falen, API’s reageren niet, context is onvolledig. Een robuust agent-systeem bereidt de agent niet voor met een stappenplan voor elke mogelijke fout — dat is onmogelijk en contraproductief. Het geeft de agent een heldere intentie mee die sterk genoeg is om op terug te vallen als het pad wegvalt: wat is het doel, wat is acceptabel als tussenresultaat, en wanneer is de situatie dermate onduidelijk dat stoppen de juiste keuze is. Maar een agent heeft geen moreel besef. Hij handelt niet vanuit waarden, maar vanuit wat zijn aansturing hem meegeeft. Dat maakt een heldere intentie bij verbreking niet optioneel — het is de enige houvast die de agent heeft.
Scenario — Claude Code — Je laat Claude Code een reeks API-integraties bouwen. Eén externe service is tijdens de sessie intermitterend beschikbaar. Zonder verbrekingsinstructie stopt Claude, rapporteert een fout, en wacht. De hele taak ligt stil. Met verbrekingsgedrag ingebouwd:
“Als een externe service niet bereikbaar is, ga dan verder op basis van de officiële documentatie en markeer de integratie als ‘requires live testing’. Ga verder met de overige integraties. Lever aan het einde een overzicht van wat getest is en wat nog validatie vereist.”
07 — Risk acceptance: overmatige controle is een groter risico dan een fout
Militair — Commandanten en ondergeschikten moeten bereid zijn risico te accepteren. Dat betekent de moed hebben om kansen te grijpen die mogelijk tot succes leiden, ook als ze tot falen kunnen leiden. Een commandant die nul fouttolerantie heeft, krijgt geen initiatief van zijn mensen. Risicomijding door overmatige controle is in mission command een groter gevaar dan een fout op de grond. Maar risico accepteren impliceert ook dat iemand verantwoordelijkheid draagt voor de uitkomst. In de krijgsmacht is die accountability helder: er is altijd een commandant die aanspreekbaar is op de beslissingen die onder zijn bevel zijn genomen.
Agent — Een engineer die elke agent-actie wil goedkeuren voordat hij wordt uitgevoerd, vernietigt het voordeel van autonomie. Fouten zijn onvermijdelijk. De vraag is of je systeem zo is ingericht dat fouten vroeg zichtbaar worden en herstelbaar zijn, niet of je ze kunt voorkomen door alles te controleren. Accepteer dat een agent soms de verkeerde keuze maakt. Bouw daar omheen. Maar waar in de krijgsmacht accountability vanzelfsprekend is, is die bij AI agents veel minder helder. Is het de engineer? De architect? De organisatie die het systeem inzet? Die vraag lost een goede aansturingsstrategie niet op, maar wie agents inzet, moet hem wel beantwoorden.
Scenario — Claude Code — Je laat Claude Code zelfstandig werken aan een nieuwe feature, maar je wilt elke bestandswijziging goedkeuren voor hij verdergaat. Het resultaat: een trage, gefragmenteerde sessie waarbij Claude zijn context verliest tussen de goedkeuringen door. Je hebt de agent zijn autonomie ontnomen en daarmee zijn effectiviteit. De risk-acceptance aanpak:
“Werk de feature volledig uit. Gebruik feature flags zodat niets live gaat zonder expliciete activatie. Schrijf tests voor elke kritieke beslissing die je neemt. Geef me aan het einde een overzicht van de keuzes die je hebt gemaakt en waarom. Dan beoordeel ik het geheel in één keer.”
Agent Command
Mission command voor AI Agents — het toevoegen van een ‘intentie-laag’ als fundament, ofwel “agent command” — is geen perfecte vertaling van ‘mission command’.
Een agent heeft geen moreel besef en accountability is minder helder dan in een militaire structuur. We kunnen een agent niet (tucht)rechtelijk vervolgen. Maar als raamwerk voor het aansturen van autonome systemen is het bruikbaarder dan de meeste alternatieven. Het is een filosofie voor iedereen die verantwoordelijk is voor het inzetten van autonome AI-systemen: engineers, architects, tech leads. Maar vooral ook de nieuwe ‘vibe-coder’ (een niet-technisch ervaren gebruiker die zijn agent software systemen laat bouwen op basis van zijn ‘vibes’).
Het is een manier van denken die niet begint bij de technologie, maar bij de vraag hoe je verantwoord richting geeft aan iets wat je niet volledig kunt controleren.
Von Moltke had geen taalmodellen. Maar het probleem dat hij oploste is tijdloos en anno 2026 — midden in de AI-revolutie — relevanter dan ooit. Meer controle is dus niet het antwoord. Betere intentie wel. En misschien is het geen toeval dat de beste vragen over agent-ontwerp klinken als vragen die commandanten al eeuwen stellen.